Concepts
The core ideas behind AVM
AVM is built around a small number of operational ideas: keep raw inventory visible, normalize identity explicitly, evaluate vulnerability conditions carefully, and preserve unresolved work as a reviewable part of the system.
From raw inventory to explainable alerts
AVM does not treat imported inventory as if it were already canonical truth. Software rows are stored with their observed values, then linked to canonical vendor and product references, then evaluated against stored vulnerability conditions.
When that process is incomplete, AVM keeps the gap visible. Unresolved mappings, alias maintenance, synonym-driven normalization, import staging, and recalculation workflows are all part of the operational model rather than side effects hidden behind a single result screen.
Core idea: AVM tries to make the path from observed inventory to operational alerting understandable.
Key terms
Raw data
Inventory-side values collected from a source system, such as vendor, product, publisher, and version strings.
Canonical
A normalized reference identity used to stabilize matching across inconsistent source-side naming.
Unresolved
A software naming case that has not yet been linked confidently to canonical vendor and product references.
Alert
An operational result created when AVM determines that software satisfies the relevant vulnerability conditions.
Raw inventory is not the same as canonical identity
One of the most important ideas in AVM is that observed inventory values are not automatically treated as stable product identity. Different sources may describe the same software in different ways. A single vendor or product may appear under multiple naming variants, packaging styles, or publisher strings.
AVM preserves those raw values because they are evidence. But it also separates them from canonical references because evidence and normalized identity are not the same thing.
Why preserve raw values
They explain what the source system actually reported and support later review.
Why normalize identity
Matching works better when it targets a stable reference instead of uncontrolled source-side strings.
Canonical linking is an explicit step
AVM treats canonical linking as a distinct operation, not an invisible implementation detail. Software records may be linked to canonical vendor and product references through normalization, alias handling, synonym support, review actions, and backfill workflows.
This matters because the quality of vulnerability matching depends heavily on the quality of canonical identity. If the system does not know what a software row really corresponds to, downstream matching should not appear more certain than the input allows.
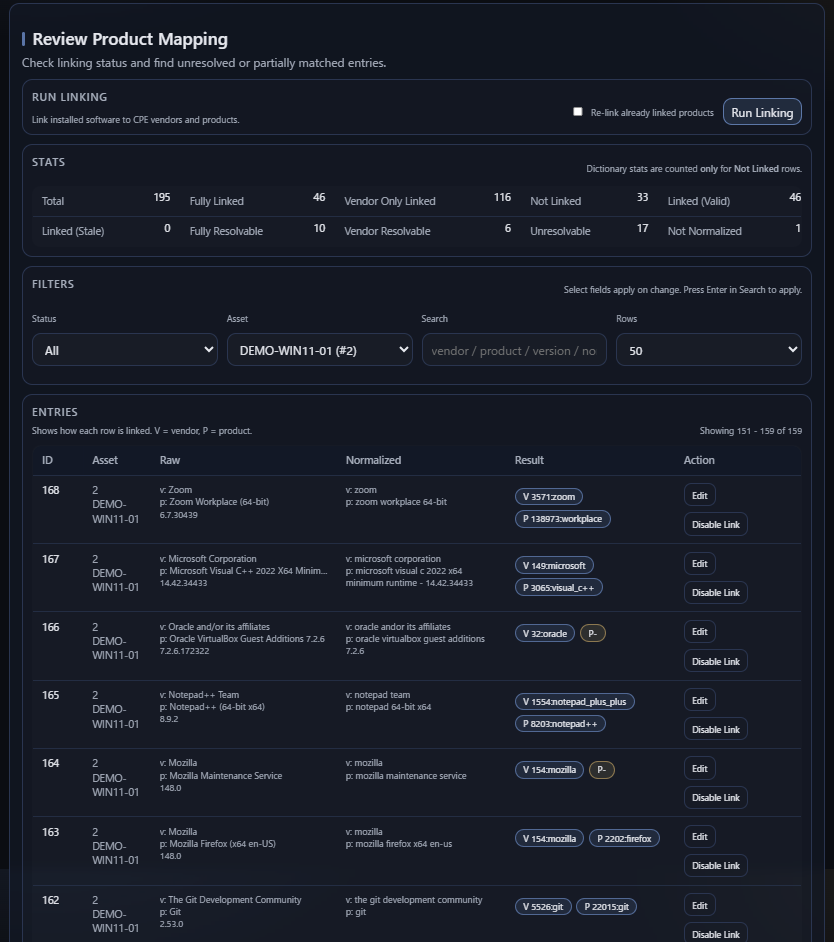
Unresolved does not mean useless
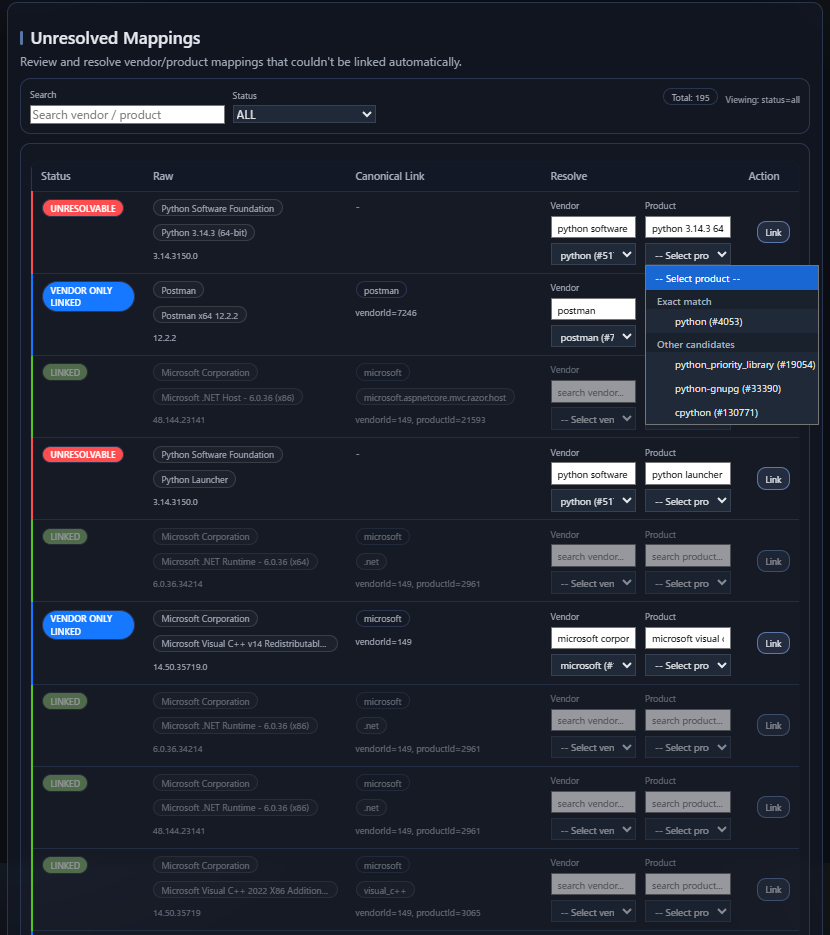
AVM keeps unresolved mappings visible because unresolved inventory is still operationally meaningful. An unresolved row is not yet ready for reliable canonical matching, but it is still evidence that the environment contains software the system needs to understand better.
This is why unresolved mappings appear as a review surface. They are not just errors to suppress. They represent naming gaps that operators can improve through alias additions, synonym handling, and canonical review.
Unresolved means
The system still needs help identifying the software confidently.
Unresolved does not mean
The row has no value, or that it should be silently ignored.
Matching is condition evaluation, not just name comparison
AVM does not treat vulnerability applicability as a pure product name problem. Canonical identity is necessary, but it is only one part of the decision. Stored vulnerability logic may include affected CPE relationships, structured criteria, and version conditions.
That means a product family match is not automatically the same thing as an affected result. The system still has to evaluate whether the vulnerability actually applies to the specific software context it knows about.
Operational distinction: “looks similar” is not the same as “satisfies the affected condition”.
Version information changes the answer
Two installations with the same product identity may not have the same exposure. A vulnerability may affect one release line or one range of versions but not another. AVM therefore treats version-aware evaluation as part of the matching concept rather than an optional extra.
This is one of the reasons AVM separates software observations, canonical identity, and vulnerability logic. The answer depends on how those pieces interact.
Same product
Two systems may share the same canonical product reference.
Different result
Their vulnerability result may still differ because the installed versions differ.
Inspectable behavior
AVM tries to make its important matching behavior inspectable. Instead of hiding all decisions behind a single opaque score, it keeps separate surfaces for observed software, canonical linkage, unresolved mappings, settings, review actions, and alert results.
This does not mean every internal detail is shown everywhere. It means the main stages of the decision path remain visible enough for operators to understand what happened and where improvements are still needed.
Visible inputs
Raw software rows, version values, and canonical linkage state remain meaningful.
Visible gaps
Unresolved cases remain reviewable instead of disappearing into background processing.
Visible outcomes
Alerts exist as a distinct operational result that can be recalculated and reviewed.
Resolution and certainty are not the same thing
A software row may be canonically resolved but still have weak version evidence. Another row may have strong raw version data but still need canonical review. AVM treats these as different issues because they affect different parts of the matching path.
In practice, this means operators can improve system quality in more than one way: by improving identity resolution, by improving source data quality, and by reviewing resulting alert state.
AVM also distinguishes between CONFIRMED and UNCONFIRMED alerts. This is separate from whether software was canonically resolved. An alert may be operationally important even when version evidence is incomplete, so AVM keeps that uncertainty visible instead of hiding it.
Operational truth and reference truth
AVM separates what was observed in the environment from what is known in the reference model. This is an important conceptual boundary.
Operational truth
What the environment appears to contain: assets, software rows, source-side values, import records, and resulting alerts.
Reference truth
Canonical vendors, canonical products, vulnerability criteria, aliases, and other normalized reference entities.
AVM becomes useful by connecting these two worlds without pretending they are already identical.
The review loop is part of the product
AVM is not only an import-and-match pipeline. It also includes a maintenance loop: review unresolved mappings, improve aliases or synonyms, run canonical backfill again, and recalculate alerts.
This matters because software naming quality is not static. Inventory sources change, environments evolve, and coverage improves over time. AVM treats that operational improvement loop as a first-class concept.
Example
A source system may report a software row using a vendor and product string that is understandable to a human but not yet linked to the canonical dictionary. AVM preserves that raw row, shows it through unresolved mapping workflows, and allows the operator to improve canonical coverage through review.
Once the software is linked to canonical vendor and product references, AVM can evaluate stored vulnerability conditions more reliably. The important point is that the system does not hide the transition from unknown identity to usable identity.
What AVM is trying to avoid
Assuming raw strings are already clean
Inventory data is useful, but it is not always normalized.
Hiding unresolved work
Gaps in identity resolution should remain visible and improvable.
Reducing matching to names alone
Vulnerability applicability depends on conditions, not only labels.
Overstating certainty
Results should reflect the quality of the available identity and version evidence.
Summary
The core concepts in AVM are simple but important: preserve raw inventory, normalize identity explicitly, evaluate vulnerability conditions carefully, and keep unresolved cases visible as part of an operational review loop.
These concepts shape the rest of the system. They explain why AVM separates software observations from canonical references, why matching is more than a name comparison, and why review and recalculation are part of normal operation.