Concepts
AVM を支える基本的な考え方
AVM は、少数の重要な運用上の考え方を土台にしています。 raw inventory を見える形で保持すること、 identity を明示的に正規化すること、 vulnerability conditions を慎重に評価すること、 そして unresolved な作業を review 可能な形で残すことです。
Raw inventory から explainable alerts へ
AVM は、import された inventory を、 そのまま canonical truth であるかのようには扱いません。 software rows はまず observed values のまま保存され、 その後 canonical vendor / product references に linked され、 さらに stored vulnerability conditions に対して評価されます。
このプロセスが未完了な場合でも、AVM はそのギャップを見えるまま保ちます。 unresolved mappings、alias maintenance、synonym-driven normalization、 import staging、recalculation workflows は、 単一の結果画面の裏に隠れた副作用ではなく、 運用モデルの一部です。
Core idea: AVM は、 observed inventory から operational alerting に至るまでの道筋を 理解可能なものにしようとしています。
主要な用語
Raw data
source system から収集された inventory-side の値です。 たとえば、vendor、product、publisher、version strings などを指します。
Canonical
source-side の不統一な naming をまたいで matching を安定させるための、 normalized reference identity です。
Unresolved
canonical vendor / product references に、 まだ十分な確信を持って linked されていない software naming case です。
Alert
software が relevant vulnerability conditions を満たすと AVM が判断したときに生成される operational result です。
Raw inventory は canonical identity と同じではない
AVM における最も重要な考え方のひとつは、 observed inventory values をそのまま stable product identity と見なさないことです。 同じ software でも source によって表現が異なることがあります。 ひとつの vendor や product が、 複数の naming variants、packaging styles、publisher strings で現れることもあります。
AVM は、それらの raw values を evidence として保持します。 しかし同時に、それらを canonical references とは分けて扱います。 evidence と normalized identity は同じものではないからです。
なぜ raw values を保持するのか
source system が実際に何を報告したかを説明でき、 後からの review に役立つからです。
なぜ identity を正規化するのか
uncontrolled な source-side strings ではなく、 stable reference を対象にした方が matching は安定するからです。
Canonical linking は明示的なステップである
AVM は canonical linking を、 見えない implementation detail ではなく、 独立した operation として扱います。 software records は、normalization、alias handling、synonym support、 review actions、backfill workflows を通じて、 canonical vendor / product references に linked されます。
これは重要です。 vulnerability matching の品質は canonical identity の品質に大きく依存するからです。 system が software row の実体を十分に理解していないのであれば、 downstream matching がそれ以上に確かなものとして見えるべきではありません。
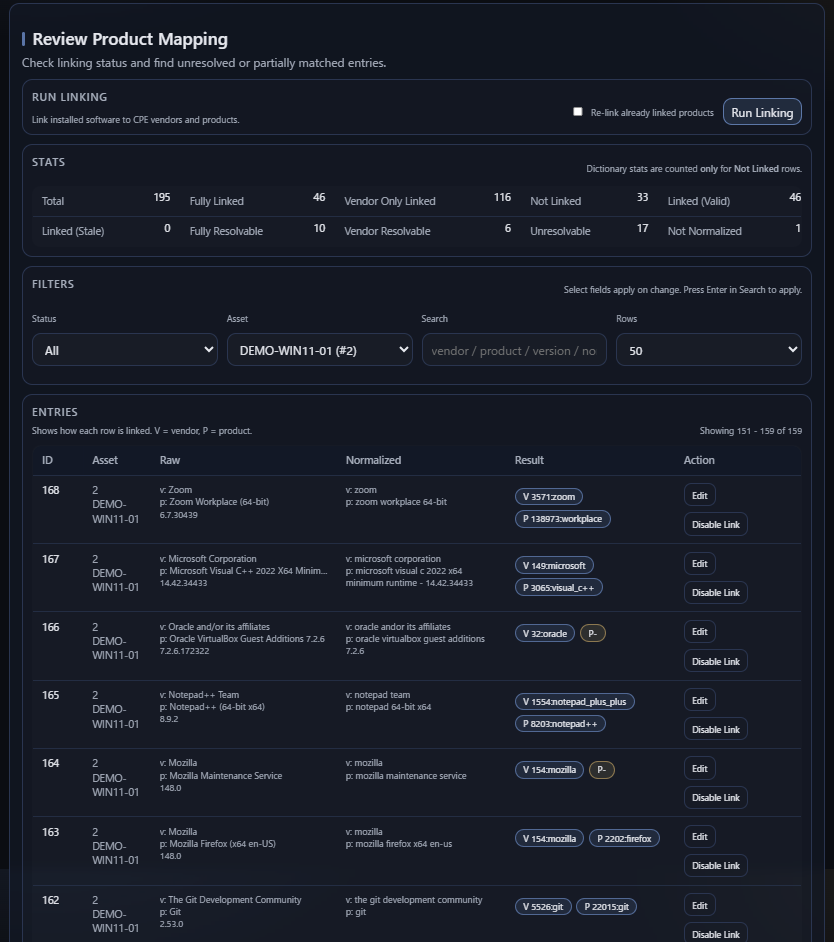
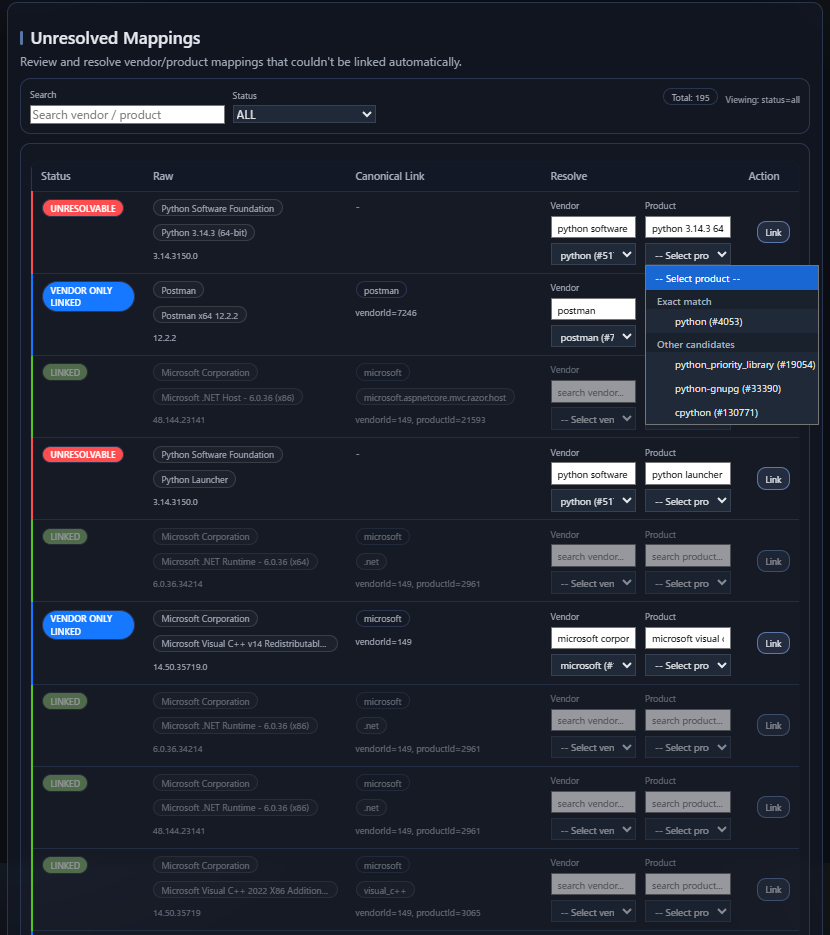
Unresolved は無価値という意味ではない
AVM は unresolved mappings を見える形で残します。 unresolved な inventory も、運用上は意味のある情報だからです。 unresolved row は、まだ信頼できる canonical matching に使える状態ではありません。 しかしそれでも、その環境に system がもっと理解すべき software が存在する、 という evidence ではあります。
そのため unresolved mappings は review surface として扱われます。 単に suppress すべき errors ではありません。 aliases の追加、synonym handling、canonical review によって operators が改善できる naming gaps を表しています。
Unresolved が意味すること
system は、その software を十分な確信を持って識別するために まだ追加の助けを必要としています。
Unresolved が意味しないこと
その row に価値がないこと、 あるいは黙って無視すべきということではありません。
Matching は単なる名前比較ではなく、条件評価である
AVM は vulnerability applicability を、 単なる product name の問題としては扱いません。 canonical identity は必要ですが、それは判断材料の一部にすぎません。 stored vulnerability logic には、affected CPE relationships、 structured criteria、version conditions が含まれることがあります。
つまり、product family が一致して見えることと、 実際に affected result になることは同じではありません。 system は、その vulnerability が実際にその software context に当てはまるかを、 さらに評価しなければなりません。
Operational distinction: 「見た目が似ている」ことと 「affected condition を満たしている」ことは同じではありません。
Version information は答えを変える
同じ product identity を持つ二つの installation でも、 exposure が同じとは限りません。 ある vulnerability は、一つの release line や一定の version range のみを 影響対象とし、別の version には当てはまらないことがあります。 そのため AVM は、version-aware evaluation を optional extra ではなく matching concept の一部として扱います。
これが、AVM が software observations、canonical identity、 vulnerability logic を分けている理由のひとつです。 結果は、それらがどう相互作用するかに依存します。
同じ product
二つの system が同じ canonical product reference を共有することがあります。
異なる結果
それでも installed versions が違えば、 vulnerability result は異なる場合があります。
Inspectable behavior
AVM は、重要な matching behavior を inspectable に保とうとします。 単一の opaque score にすべてを隠すのではなく、 observed software、canonical linkage、unresolved mappings、 settings、review actions、alert results それぞれを 別々の surface として持っています。
これは、すべての内部詳細をどこでも見せるという意味ではありません。 重要なのは、decision path の主要な段階が、 operator にとって十分に見える状態に保たれ、 何が起きたのか、どこにまだ改善余地があるのかを理解できることです。
Visible inputs
raw software rows、version values、 canonical linkage state は、それぞれ意味を持ったまま残ります。
Visible gaps
unresolved cases は、 background processing の中に消えるのではなく、 review 可能な形で残ります。
Visible outcomes
alerts は、再計算や review が可能な 独立した operational result として存在します。
Resolution と certainty は同じではない
software row が canonically resolved されていても、 version evidence は弱いかもしれません。 逆に、raw version data は十分でも、 canonical review はまだ必要かもしれません。 AVM はこれらを別の問題として扱います。 それぞれ matching path の異なる部分に影響するからです。
実運用では、system quality を改善する方法は一つではありません。 identity resolution を改善すること、 source data quality を改善すること、 そして resulting alert state を review すること、 いずれも重要です。
AVM はまた、CONFIRMED と UNCONFIRMED の alerts を区別します。 これは software が canonically resolved されているかどうかとは別の話です。 version evidence が不完全でも、その alert は operationally 重要かもしれません。 そのため AVM は、その uncertainty を隠さず可視化します。
Operational truth と reference truth
AVM は、環境で観測されたものと、 reference model 側で既知のものを分けて扱います。 これは重要な conceptual boundary です。
Operational truth
環境に存在しているように見えるものです。 assets、software rows、source-side values、 import records、resulting alerts などが含まれます。
Reference truth
canonical vendors、canonical products、 vulnerability criteria、aliases、 その他の normalized reference entities です。
AVM は、この二つの世界が最初から同一であるかのようには扱わず、 それらを接続することで意味を持ちます。
Review loop は製品の一部である
AVM は、単なる import-and-match pipeline ではありません。 そこには maintenance loop があります。 unresolved mappings を review し、 aliases / synonyms を改善し、 canonical backfill を再実行し、 alerts を再計算する、という流れです。
これは、software naming quality が固定ではないから重要です。 inventory sources は変わり、 environments は進化し、 coverage は時間とともに改善していきます。 AVM は、この operational improvement loop を first-class concept として扱います。
Example
source system が、 人間には理解できるが canonical dictionary にはまだ linked されていない vendor / product string で software row を報告することがあります。 AVM はその raw row を保持し、 unresolved mapping workflows を通じて可視化し、 operator が review を通じて canonical coverage を改善できるようにします。
software が canonical vendor / product references に linked されると、 AVM は stored vulnerability conditions を より信頼性高く評価できるようになります。 重要なのは、system が unknown identity から usable identity への移行を 隠さないことです。
AVM が避けようとしていること
Raw strings が最初から整っていると仮定すること
inventory data は有用ですが、 常に normalized されているわけではありません。
Unresolved work を隠すこと
identity resolution の gaps は、 見える形で残り、改善できるべきです。
Matching を名前比較だけに還元すること
vulnerability applicability は、 labels だけでなく conditions に依存します。
Certainty を実態以上に見せること
results は、利用可能な identity / version evidence の質を 反映するべきです。
まとめ
AVM の core concepts はシンプルですが重要です。 raw inventory を保持すること、 identity を明示的に正規化すること、 vulnerability conditions を慎重に評価すること、 そして unresolved cases を operational review loop の一部として見えるまま残すことです。
これらの concepts は system 全体の設計に影響しています。 software observations と canonical references を分ける理由、 matching が単なる名前比較ではない理由、 review と recalculation が通常運用の一部である理由は、 ここから説明できます。