Observed inventory
AVM stores software as it was observed, including source-side vendor, product, publisher, and version context.
Open-source asset-aware vulnerability management
AVM helps you review how software is linked, how vulnerability conditions are evaluated, and why alerts are generated.
Try AVM
LiveExplore AVM with a preloaded environment. No setup required.
What AVM enables
About
Many environments can collect software inventory. The harder part is understanding what that software actually is, how reliably it maps to canonical references, and whether stored vulnerability conditions really apply.
AVM is designed around that distinction. It keeps observed software visible as raw evidence, resolves canonical identity explicitly, evaluates vulnerability applicability carefully, and preserves unresolved cases as part of the operating model.
AVM stores software as it was observed, including source-side vendor, product, publisher, and version context.
AVM links software to canonical vendor and product references so downstream matching does not depend only on unstable raw strings.
AVM creates alerts as a distinct result of evaluating software against stored vulnerability conditions.
Target Use Cases
AVM emphasizes transparency and interpretability in vulnerability management:
AVM keeps visible how assets and software are connected to CPEs instead of hiding the linkage behind opaque automation.
AVM helps operators understand why vulnerabilities are considered applicable by separating identity resolution, criteria logic, and version-aware evaluation.
AVM preserves unresolved mappings as reviewable work so gaps in canonical coverage remain understandable and improvable.
To support this, AVM is designed for small-scale environments, proof-of-concept deployments, and learning or research use.
This makes AVM a practical tool for understanding, validating, and refining vulnerability management logic before scaling to larger environments.
Vision
While AVM currently targets smaller environments, its longer-term goal is broader:
To eliminate situations where vulnerability management is left unaddressed due to cost or resource constraints.
In many organizations, especially those with limited budgets or personnel, introducing a full-scale commercial vulnerability management platform is not always feasible. As a result, vulnerability management may remain partially implemented—or in some cases, not implemented at all.
AVM aims to bridge this gap.
AVM provides a practical starting point for environments that need useful vulnerability management without large-scale platform overhead.
Matching logic, review state, and uncertainty remain visible so operators can understand what the system is doing and why.
AVM allows users to control how software is linked to CPEs, making adoption safer and more understandable in smaller environments.
The goal is not to replace enterprise-grade platforms, but to ensure that:
“No environment is left without a viable starting point for vulnerability management.”
AVM exists to make vulnerability management accessible, understandable, and actionable — even in environments where traditional solutions are out of reach.
Why AVM is different
AVM is built for environments where software naming is imperfect, canonical coverage improves over time, and applicability decisions need to be understandable rather than hidden behind a black box.
AVM uses canonical vendor and product references to stabilize matching across inconsistent source-side naming.
AVM evaluates affected CPE relationships, criteria logic, and version conditions rather than treating similarity as proof.
Unresolved mappings, aliases, synonyms, backfill, and recalculation are visible parts of normal operation.
Workflow
AVM is easiest to understand as a repeating workflow, not as a single import action or a single alert screen.
This loop is part of normal operation. It is how AVM improves coverage over time without discarding raw inventory evidence.
Features
AVM brings together inventory handling, canonical software identity, structured vulnerability evaluation, and review-oriented administration.
Software is tied to assets so inventory and alerting stay grounded in host context.
Assets and software are validated into staging before becoming part of the main operational model.
Raw software names can be connected to normalized vendor and product references through reviewable resolution workflows.
Matching uses affected CPE relationships, criteria structure, and version-aware evaluation.
Incomplete canonical coverage remains visible through unresolved mapping and review surfaces.
Alerts are created and recalculated as a distinct operational result, not as an invisible side effect.
Aliases, synonyms, settings, and sync workflows support ongoing improvement of system quality.
Runs, settings, user management, and audit-related records help keep operation understandable over time.
Architecture
AVM separates raw inventory, canonical references, vulnerability logic, and operational results into distinct but connected layers.
Import does not erase source-side naming or context. AVM keeps raw software values visible for later review.
Canonical vendors, products, aliases, synonyms, and vulnerability conditions live in their own reference layer.
Alerts are stored as operational results that can be reviewed, recalculated, and improved as coverage changes.
Docs
The docs are organized around how AVM actually works, not only around screen names.
Follow the first operational path through import, review, sync, recalculation, and alert inspection.
Understand raw inventory, canonical identity, inspectability, and the review loop.
See how assets, software, canonical references, vulnerability entities, alerts, and admin records are structured.
Learn how AVM evaluates affected software using canonical linkage, criteria, and version-aware logic.
See how staged import works and why successful import is not the same as full canonical resolution.
Understand the maintenance loop behind sync, unresolved review, aliases, backfill, recalculation, and settings.
Roadmap
AVM is already structured around canonical identity, staged import, structured matching, and operational review. Current work continues to improve the quality, visibility, and usability of that model.
Improve the Japanese-language user interface so the product is easier to operate and explain in Japanese-speaking environments.
Provide AVM through Docker so setup, evaluation, and self-hosted use are easier and more consistent across environments.
Add scheduling for Update KEV Catalog, CVE Delta Update (API), and Generate alerts, and add notifications for Generate alerts execution results.
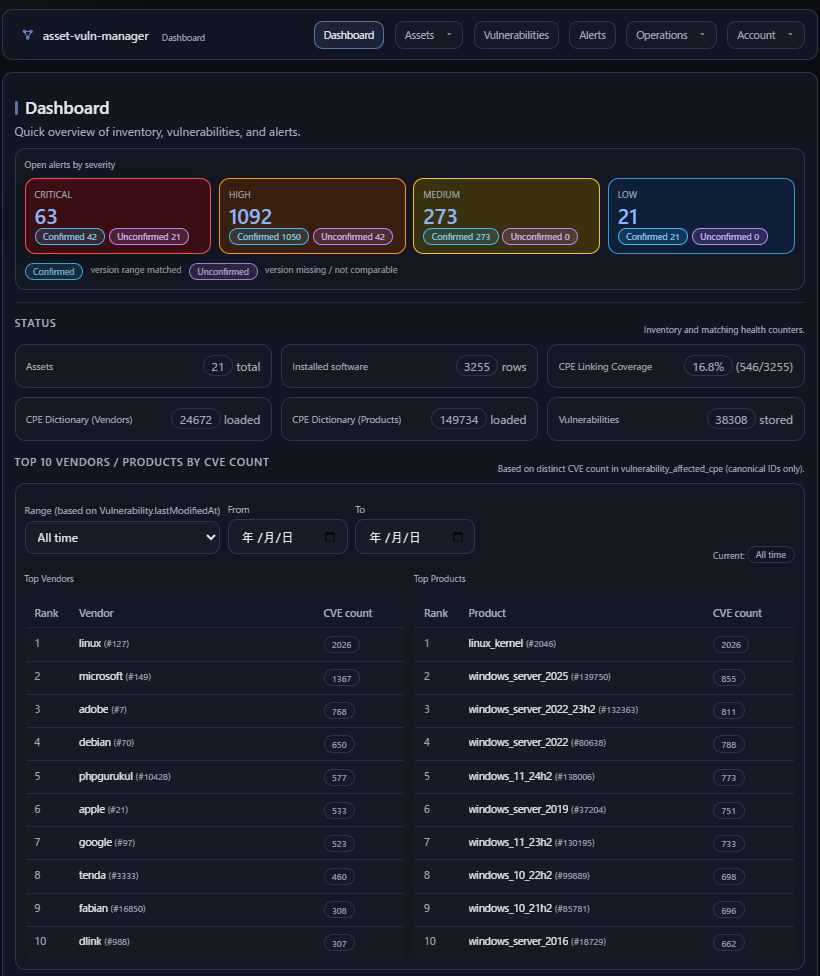
Add more useful information to the dashboard so important operational state is visible earlier and with less navigation.
Continue to strengthen docs around the real data model, matching behavior, import flow, and operating loop.
Support SBOM formats (CycloneDX, SPDX) as an additional inventory source, aligning component data with AVM’s canonical model to extend vulnerability evaluation beyond host-level software.